
La inteligencia artificial conversacional ha dejado de ser una promesa para convertirse en una herramienta de negocio rentable. En 2026, prácticamente cualquier empresa puede ofrecer atención al cliente automatizada a través de WhatsApp, web o aplicaciones internas. Pero hay una diferencia fundamental entre conectar un chatbot SaaS y construir un asistente de IA realmente útil: el primero responde con información genérica, el segundo dialoga con los datos de tu empresa, ejecuta acciones en tu ERP y aprende de tus propios procesos.
Si estás desarrollando un ERP a medida en Python y Django o en cualquier otro lenguaje moderno y quieres incorporar un asistente de IA que entienda tu negocio, necesitas una arquitectura capaz de combinar tres elementos: un modelo de lenguaje (LLM), una base de conocimiento propia (mediante un sistema RAG) y una capa de canales (WhatsApp, web, email) que conecte al cliente con el sistema. En este artículo desglosamos cómo abordar esta integración de forma profesional, escalable y conforme a las nuevas políticas de Meta.
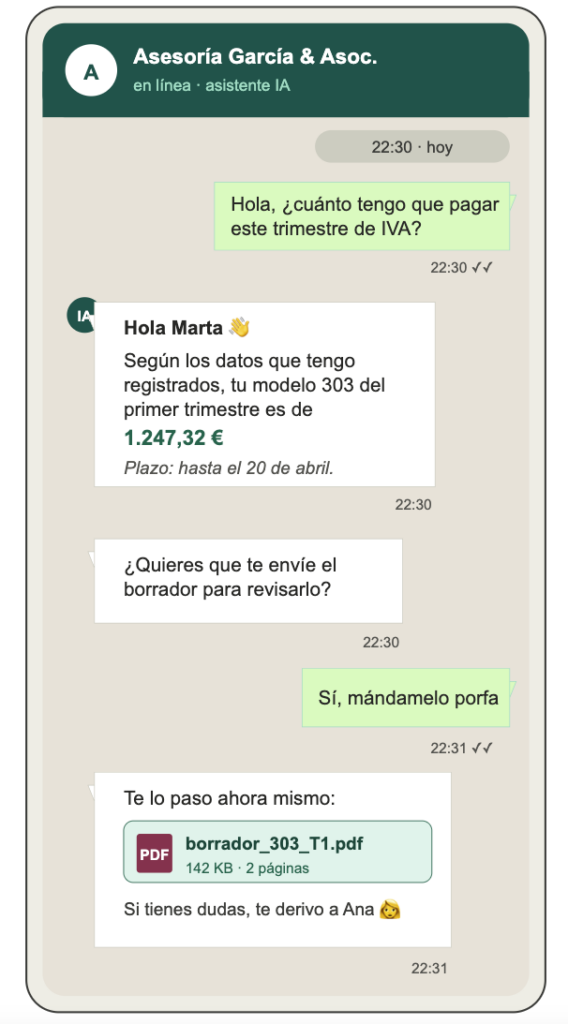
¿Por qué un asistente conversacional necesita estar conectado a tu ERP?
Un chatbot tradicional responde preguntas frecuentes a partir de un guion cerrado. Funciona para resolver dudas básicas (horarios, ubicación, políticas de devolución), pero falla en cuanto el cliente pregunta algo específico de su cuenta:
- “¿Cuándo me llega el pedido 4521?”
- “¿Cuál es el saldo de mi factura del mes pasado?”
- “Quiero modificar la potencia contratada en mi suministro.”
- “¿Cuánto he consumido este trimestre?”
Estas preguntas no se responden con un guion: requieren consultar el ERP en tiempo real, recuperar información del cliente concreto y, a veces, ejecutar una acción (crear un ticket, modificar un dato, generar un documento). Aquí es donde un asistente de IA conectado al backend marca la diferencia.
Además, hay un cambio normativo importante: desde el 15 de enero de 2026, Meta restringe el uso de asistentes de IA de propósito general en WhatsApp Business. Solo se permiten soluciones con un caso de uso empresarial claro, lo que en la práctica significa que los bots tipo “ChatGPT genérico conectado a WhatsApp” están fuera. Lo que sí se permite (y se fomenta) es exactamente lo que vamos a describir aquí: un asistente que resuelve consultas operativas concretas conectándose a los sistemas de la empresa.
Arquitectura recomendada: las seis capas de un asistente de IA empresarial
Un asistente de IA de producción no es “un LLM enchufado a WhatsApp”. Es un sistema en capas donde cada componente cumple una función específica. Esta es la arquitectura que recomendamos para entornos Python/Django:
| Capa | Tecnología recomendada | Función |
|---|---|---|
| Canales | WhatsApp Business API (vía Meta Cloud o BSP), webhook web, email | Recibir y enviar mensajes |
| Orquestador | Django + LangChain o LangGraph | Decidir qué hacer con cada mensaje |
| Modelo LLM | Claude, GPT-5, Gemini o Mistral (vía API) | Comprensión y generación de lenguaje |
| Base de conocimiento | PostgreSQL + pgvector (o Qdrant, Chroma) | Recuperar información propia (RAG) |
| Tareas asíncronas | Celery + Redis | Procesar mensajes sin bloquear webhooks |
| Capa de acciones | Tool calling sobre la API interna del ERP | Ejecutar consultas y acciones reales |
El corazón del sistema: RAG (Retrieval-Augmented Generation)
El gran salto de calidad respecto a un chatbot convencional viene de RAG, la técnica que permite a un LLM responder con información de tu propia empresa sin necesidad de reentrenarlo. El flujo es el siguiente:
- Cuando llega una pregunta del cliente, el sistema convierte la pregunta en un vector de embeddings (representación numérica del significado).
- Busca en la base de conocimiento los fragmentos de documentos más similares a esa pregunta.
- Envía al LLM la pregunta original junto con los fragmentos recuperados como contexto.
- El LLM genera una respuesta fundamentada en los documentos reales de la empresa, no en su conocimiento genérico.
Esto evita las temidas “alucinaciones” del LLM y permite que el asistente responda sobre manuales internos, condiciones contractuales, procesos específicos o cualquier documentación propia.

Más allá de RAG: function calling y acciones reales sobre el ERP
RAG resuelve preguntas de información, pero un asistente verdaderamente útil también debe ejecutar acciones. Aquí entra el function calling (o tool use): le damos al LLM una lista de funciones disponibles y él decide cuándo llamarlas.
Por ejemplo, si un cliente pregunta “¿cuál es el estado de mi pedido 4521?”, el LLM no debe inventar la respuesta: debe llamar a una función que devuelva el estado actual del pedido.
Detalle de seguridad clave: existen muchos datos que nunca los proporcionará el LLM ni el cliente en el chat. Lo inyectamos nosotros en el servidor a partir del número de WhatsApp del remitente o del usuario autenticado en la web. De lo contrario, abriríamos un agujero por el que un cliente podría consultar pedidos de otros.
Consideraciones críticas para entornos de producción
Hay tres aspectos que diferencian un proyecto que escala de un piloto que se queda apagado a los tres meses:
Trazabilidad y logs: cada conversación, cada llamada al LLM y cada acción ejecutada sobre el ERP debe quedar registrada. No solo por cumplimiento (RGPD), sino porque los logs son la fuente principal para mejorar el sistema. Una buena práctica es guardar pregunta, contexto recuperado, respuesta generada y herramientas invocadas en una tabla dedicada.
Handoff a humano: el asistente debe saber cuándo no sabe. Cuando detecta una intención compleja (reclamación, queja formal, caso fuera de su alcance) debe escalar a un agente humano sin perder el contexto de la conversación. Implementar esto bien suele suponer la diferencia entre un cliente satisfecho y uno frustrado.
Coste por conversación: cada mensaje supone llamadas a APIs de pago (LLM, embeddings) y mensajes facturados por Meta. Sin caché de respuestas frecuentes, sin control de tokens y sin priorización del modelo según la complejidad de la consulta, el coste se dispara. Una arquitectura bien planteada combina un modelo barato para clasificar la intención y solo escala al modelo caro cuando es necesario.
Conclusión
Integrar un asistente de IA con un ERP a medida no consiste en “enchufar ChatGPT a WhatsApp”. Consiste en construir una arquitectura en capas donde el LLM se convierte en el cerebro conversacional, RAG le aporta la memoria propia de tu empresa, las herramientas le permiten ejecutar acciones reales y los canales le dan la voz para hablar con tus clientes donde están.
El stack Python + Django + PostgreSQL + Celery + LangChain encaja perfectamente con este modelo y permite mantener todo el control de los datos en tu propia infraestructura, sin depender de un SaaS que mañana puede cambiar de precio, de políticas o, como hemos visto en enero de 2026 con Meta, prohibir directamente lo que estabas haciendo.
En FocusSoft llevamos años desarrollando este tipo de integraciones para empresas que necesitan un asistente realmente conectado a su negocio, no un chatbot genérico. Si estás valorando dar este paso, contar con un desarrollo a medida en tecnologías sólidas y con experiencia en sectores complejos es la mejor garantía de que el proyecto no se queda en piloto y llega a producción con valor real para tus clientes.